- Published on
为什么说逻辑回归是单一神经元?
- Authors

- Name
- Jason Huang
- @zesenhhh
假设你已经了解了逻辑回归这基础但经典的机器学习算法,不是很清楚的话可以参考我的其他文章: 极大似然估计与逻辑回归有什么关系? - 掘金 。 同时假设对神经网络也有一定的了解。
Multi-layer Perceptron
让我们先简单回顾一下多层感知机(即神经网络)。 多层感知器(Multi-layer Perceptron,简称 MLP)是一种前馈人工神经网络模型,它能够对输入的数据进行非线性变换,常用于解决各种复杂的模式识别和分类问题。MLP 由多个层次组成,包括一个输入层、一个或多个隐藏层(hidden layer)以及一个输出层。
- 输入层
- 输入层接收外部数据。这一层的神经元数量通常等于特征的数量。输入层不进行任何计算,只是将数据传递到下一层。
- 隐藏层(hidden layer)
- 隐藏层是 MLP 的核心,它们位于输入层和输出层之间。可以有一个或多个隐藏层。
- 每个隐藏层包含一定数量的神经元,神经元之间不相连,但每个神经元都与上一层的所有神经元相连,并对来自上一层的信号进行加权求和,加上一个偏置项,然后通过一个非线性激活函数进行处理。
- 常用的激活函数包括 Sigmoid、tanh、ReLU 等。这些非线性激活函数使得多层感知器能够学习和表示复杂的非线性模式。
- 输出层
- 输出层负责产生网络的最终输出。对于分类问题,输出层的神经元数量通常等于类别的数量,且常使用 Softmax 激活函数来将输出转化为概率分布。
- 对于回归问题,输出层通常只有一个神经元,且不使用激活函数或使用恒等激活函数。
- 学习过程
- MLP 的学习过程通常使用反向传播算法(Backpropagation)。在这个过程中,网络通过输入数据进行前向传播,计算每一层的输出,然后通过与真实标签的比较产生误差。
- 这个误差通过网络反向传播,通过计算误差对每个权重的偏导来更新权重,这个过程通常结合梯度下降或其变体进行优化。
以下是单隐层的感知机示例图:
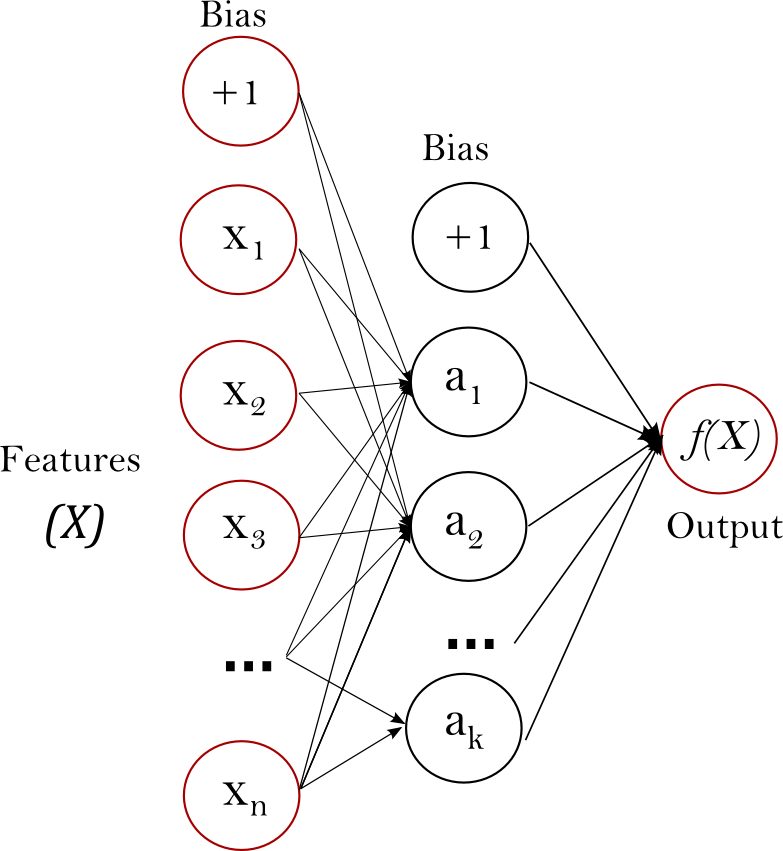
根据图示:
- 输入层一共接收了 个特征:,外加一个偏置项 Bias;
- 隐层由 个神经元组成:,每个神经元分别接收 n 个特征进行加权求和;
- 最后输出一个维度的 output(根据任务决定是否使用激活函数)。
Logistic regression

跟上面的 MLP 图像相比,两者的初始步骤都涉及对输入特征进行线性加权和添加偏置。
主要区别在于架构的复杂性和层数:
- MLP 可以有多个层次的神经元,每个神经元可以看作执行类似逻辑回归的计算,但通常使用不同的激活函数(ReLU、tanh等)。
- 逻辑回归 本质上执行的是单个 MLP 神经元所做的工作:计算输入的加权和及偏置,然后应用sigmoid激活函数以输出概率。
Conclusion
逻辑回归等同于使用 sigmoid 激活函数的单神经元 MLP。这个神经元直接将输入特征映射到输出概率,实际上执行的计算与逻辑回归模型相同。因此,逻辑回归可以被视为MLP 的一个特殊、更简单的情况,其中网络只由一个神经元组成。
MLP 由于采用了多个神经元与多个隐藏层进行交互学习,配合其他非线性函数,使其能够捕捉和建模数据中的复杂非线性关系,通过增加更多的层和神经元来提升模型的表达能力,适用于大规模数据集,实践中利用 MLP 搭建起来的深度学习的效果也是有目共睹。
但深度学习相比 LR 所需的计算资源会更多,且可解释性是一直以来被诟病的点(当然我们也可以说效果好就行,DL 也确实效果好)。相比于 LR 就是一个单一神经元,有多少特征就有多少参数(加上 bias),我们能很直观的看到特征变化引起的参数权重变化,再看到通过 sigmoid 输出概率的变化。
但是当输入的特征维度越来越大,神经元越来越多,隐藏层数越来越多,参数权重越来越多(比如 GPT),这其中的权重流动与学习复杂得超过人脑能想象的地步,人们难以解释其中的细节:为什么输入这些特征,某些神经元被激活,就会导致这样的结果?GPT 输出的回答是依据哪些文本?尽管人们能够根据 attention 等机制获取某些重要的权重特征,从而更好的理解transformer,但目前神经网络的黑箱属性还是比较重的。

